出现这个错误是因为存储引擎 innoDB 不支持 delayed 操作,请检查表类型,更改为 MyISAM。详见官网说明:http://dev.mysql.com/doc/refman/5.6/en/insert-delayed.html
error: ‘stoi’ was not declared in this scope
已经 include 了相应的头文件 string,但是在调用 stoi 函数时提示编译错误:error: ‘stoi’ was not declared in this scope,在谷歌上搜索了一番,原来需要使用 C++11 标准进行编译,改编译命令如下:
g++ filename.cpp -std=c++11
问题解决。
MySQL 建表出现 1064 错误
几乎没有手写过建表语句的人今天想建一个表将一个 csv 文件导入进行分析,SQL 写好了,运行出现错误码 1064, 但是没有文字描述错在哪里,为了分析错误原因,将字段改为最简单的形式,还是出错:
create table table_name (
id unsigned int not null auto_increment,
name varchar(20),
primary key (id)
) default charset utf8
错误信息如下:
#1064 – You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near ‘unsigned int not null auto_increment, name varchar(20), primary key (‘ at line 2
看了半天不知道错在哪里了,叫室友帮忙看一眼,他说,unsigned 应该在 int 后面啊,我试了一下,果然成功运行。
更改后的 SQL 如下:
create table table_name (
id int unsigned not null auto_increment,
name varchar(20),
primary key (id)
) default charset utf8
无符号整形不应该是 unsigned int 吗? C 语言就是这样定义的啊,额~
PHP 中数组获取不到元素
早上看到 SO 上一个有关 PHP 的问题,提问者描述有一个数组,使用 print_r 可以看到索引 key 和相对应的 value 都是存在的,但是访问该元素,不管是使用 array[key] 还是 array[‘key’] 这两种访问形式,都提示 Undefined offset 而取不到数据。举例描述提问者的问题,假设一个数组 $a,print_r($a) 的输出为
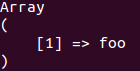
可以看到数组存在索引 1 值为 foo,当使用 $a[1] 或者 $a[‘1’] 访问索引为 1 的元素,都提示 Undefined offset,这就有点让人费解了,下文将讲解这个问题产生的原因,以及如何得到像这样奇怪的一个数组。
首先说明一点,PHP 中数组的 key 可以为整形和字符串,但是包含有合法整型值的字符串会被转换为整型。例如键名 “1” 实际会被储存为 1。来看一个例子,考虑如下代码:
$a = array(
1 => 'foo',
'1' => 'bar',
'name' => 'upliu',
);
print_r($a);
var_dump($a);
将会输出:
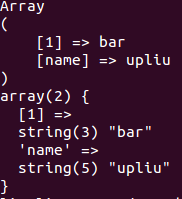
可以看到存入到数组里面的 1 为数值索引(注意索引 name 加了引号,说明索引 name 为字符串索引(这不废话嘛,’name’ 肯定是字符串啊)),并且值为 bar 覆盖了先出现的 foo,$a[1] 和 $a[‘1’] 都能正确读取到 bar,且没有任何错误警告提示,说明这个两者都是可用的(笔者在此猜测 $a[‘1’] 实际上完全等效于 $a[1],PHP 数组读取元素的时候会将数值字符串索引转换为数值索引)。
我们先还原一下提问者的问题,看如何生产出那样一个数组。考虑如下代码:
$json = '{"1":"foo"}';
$o = json_decode($json);
var_dump($o);
将会输出
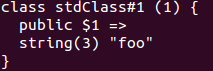
这个结果很显而易见,$o 为一个对象,有一个属性为 1,因为该属性并不是合法的 PHP 标识符,因此不能使用箭头的方式访问,我们使用强制类型转换将该对象转换为一个数组:
$a = (array)$o; print_r($a);
将会输出

接下来尝试访问数组 $a 的索引为 1 的元素:
echo $a[1], PHP_EOL; echo $a['1'], PHP_EOL;
上面两条语句均会报错 Undefined offset,这时数组 $a 就是 SO 上那位提问者遇到问题时碰到的数组了,BUG 重现是一件很爽的事啊。
我们来直接将上面代码中的 json 串解析为数组:
$a2 = json_decode($json, true); print_r($a2); echo $a2[1], PHP_EOL; echo $a2['1'], PHP_EOL;
将会输出
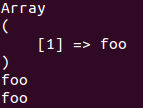
一切正常,这个时候问题来了,明明数组 $a 和数组 $a2 使用 print_r 输出一模一样,为什么一个元素可以访问,另一个却不能访问。我们用更强大的 var_dump 看看:
var_dump($a); var_dump($a2);
将会输出
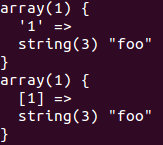
从这个输出我们可以看到数组 $a 和 $a2 的不同,通过将对象强制类型转换得到的数组 $a 拥有一个字符串 ‘1’ 的索引(可以使用 var_dump(array_keys($a))来证实这一点),而我们使用 $a[1] 和 $a[‘1’] 都是访问数组 $a 中索引为 1 的元素,而 $a 并不存在该元素,因此出现错误 Undefined offset。
小结:PHP 默认不会存储整型字符串的索引,会将其转换为数值,在将对象转换为数组的过程中可能引入整型字符串的索引,如果给出索引为整数或整形字符串,访问数组元素都会去获取数组的对应数值索引。
本文实例完整代码如下:
<?php
$json = '{"1":"foo"}';
$o = json_decode($json);
$a = (array)$o;
print_r($a);
echo $a[1], PHP_EOL;
echo $a['1'], PHP_EOL;
$a2 = json_decode($json, true);
print_r($a2);
echo $a2[1], PHP_EOL;
echo $a2['1'], PHP_EOL;
var_dump($a);
var_dump($a2);
var_dump(array_keys($a));
var_dump(array_keys($a2));
foreach ($a2 as $k => $v) {
var_dump($k);
var_dump($v);
}
foreach ($a as $k => $v) {
var_dump($k);
var_dump($v);
}
各种语言实现函数累加器函数
这两天都在看《黑客与画家》,作者 Paul Graham 是一个推崇 Lisp 为编程能力最强的语言的支持者。第13章,作者各种强调 Lisp 的强大,最后在该章节末尾给出了一个例子来说明各个编程语言的能力是不一样的,Lisp 是最强大的。
原文引入如下:
为了解释我所说的语言编程能力不一样,请考虑下面的问题。我们需要写一个函数,它能够生成累加器,即这个函数接受参数 n,然后返回另一个函数,后者接受参数 i,然后返回 n 增加了 i 后的值。「这里说的是增加,而不是 n 和 i 的相加(plus)。累加器就是应该完成 n 的累加。」
接下来,作者了给出了各种语言实现上述问题的写法:
Common Lisp:
(defun foo (n) (lambda (i) (incf n i)))
Scheme:
(define (foo n) lambda (i) (set! n (+ n i) n))
Goo:
(df foo(n) (op incf n _))
Arc:
(def foo (n) [++ n _])
作者把 Scheme, Goo, Arc 这三种语言称作 Lisp 的方言(哈哈哈,大概是想说,这些都是在模仿 Lisp 吧)
Ruby:
def foo (n)
lambda {|i| n += i} end
Perl:
sub foo {
my ($n) = @_;
sub {$n += shift}
}
Smalltalk:
foo: n |s| s := n. ^[:i| s := s+i. ]
Javascript:
function foo(n) {
return function (i) {
return n += i; } }
Python:
def foo(n):
s = [n]
def bar(i):
s[0] += i
return s[0]
return bar
作者还提到,Python 用户完全可以合理地质疑为什么不能写成下面这样,并且他猜想,Python 有一天会支持这样的写法:
def foo(n):
return lambda i: return n += i
或者:
def foo(n):
lambda i: n += i
Python 采用面向对象模拟闭包的实现:
def foo(n):
class acc:
def __init__(self, s):
self.s = s
def inc(self, i):
self.s += i
return self.s
return acc(n).inc
或者:
class foo:
def __init__(self, n):
self.n = n
def __call__(self, i):
self.n += i
return self.n
其他语言根本无法解决这个问题,肯 安得森说,Java 只能写出一个近视的解法:
public interface Inttoint {
public int call(int i);
}
public static Inttoint foo(final int n) {
return new Inttoint () {
int s = n;
public int call(int i) {
s = s + i;
return s;
}};
}
感觉这个就比较精彩了,我看得懂只有 js、java 和 python,perl 虽然去年看过一本 perl 入门的书,但是现在已经忘干净了。
作者还强调,其他语言无法解决这个问题,这句话并不完全正确。因为所有编程语言都是图灵等价的,意味着可以使用任何一种语言写出任何一个程序。只不过不同语言实现起来难度和复杂度不一样而已。
Lisp 的那种写法,看得我好别扭,还是看 js 最舒服。
解决 CENTOS ssh 连接上后乱码问题
1、更改 /etc/sysconfig/i18n 里的 LANG 为 “en_US.UTF-8″;
2、更改 /etc/profile 里的 LANG 为 “en_US.UTF-8″;
3、更改 /home/YOUR_NAME/.bashrc 里的 LANG(如果有该项就更改,没有不用管) 为 “en_US.UTF-8″;
其实解决乱码问题很简单,只要保持各个地方编码方式一致(当然,上面你要改为 “zh_CN.GB18030” 也是可以的)就 OK 了,依次检查系统语言设置有关的配置文件,都更改为想要的编码方式(这里主要是为了防止用户个人设置被修改,其实只需要在 .bashrc 里面指定编码就OK了,因为个人设置会覆盖系统的默认设置),然后使用客户端 putty 或者 SecureCRT 更改编码方式和上面设置保持一致,就不会出问题了。
微调了博客主题
在原主题的基础上适当做了一些修改。
还是两栏布局,目前,左边文章主题部分随着窗口大小自动调整,右边边栏宽度固定。这就是我要的效果。
还有若干小问题:1、边栏和主体中间要隔一定距离才好看一些,但是目前没找到好的方法如何写 css。2、之前的 rss订阅 按钮删除了,因为没调合适,这个按钮加在哪里合适呢。
PHP 支持汉字的反转字符串函数
PHP 里面有一个自带的函数 strrev,该函数可以将字符串反转,例如:
$str = 'abcdef'; echo strrev($str);
将输出:
fedcba
但是该函数并不支持中文,如果字符串含有中文,那么汉字将会乱码。
写了一个支持反转包括汉字的字符串反转函数:
function mb_strrev($str) {
$len = mb_strlen($str, 'UTF-8');
$arr = array();
for ($i = 0; $i < $len; $i++) {
$arr[] = mb_substr($str, $i, 1, 'UTF-8');
}
return implode('', array_reverse($arr));
}
使用示例:
$str = '记者获some-letters-here悉嫦娥二号发射工作准备全部就绪'; echo mb_strrev($str);
MySQL JOIN 用法示例详解
本文将图文并茂的讲解 MySQL 的查询时 JOIN 的用法。这里用到的两个示例表及示例数据如下:
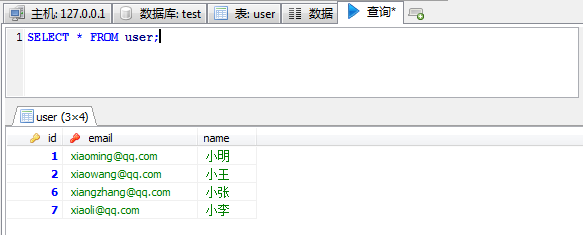
CREATE TABLE `user` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `email` varchar(255) NOT NULL, `name` varchar(255) NOT NULL, PRIMARY KEY (`id`), UNIQUE KEY `users_email_unique` (`email`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; INSERT INTO `user` VALUES (1,'xiaoming@qq.com','小明'),(2,'xiaowang@qq.com','小王'),(6,'xiangzhang@qq.com','小张'),(7,'xiaoli@qq.com','小李'); CREATE TABLE `user_info` ( `user_id` int(10) NOT NULL, `age` int(10) NOT NULL, `name` varchar(255) NOT NULL, PRIMARY KEY (`user_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; INSERT INTO `user_info` VALUES (1,22,'小明'),(2,21,'小王'),(3,33,'小郑');
插入数据库后数据如下:

MySQL 官网上介绍 JOIN 一共有以下几种形式,接下来笔者将一一介绍:
table_reference [INNER | CROSS] JOIN table_factor [join_condition]
| table_reference STRAIGHT_JOIN table_factor
| table_reference STRAIGHT_JOIN table_factor ON conditional_expr
| table_reference {LEFT|RIGHT} [OUTER] JOIN table_reference join_condition
| table_reference NATURAL [{LEFT|RIGHT} [OUTER]] JOIN table_factor
JOIN、CROSS JOIN、INNER JOIN
MySQL 官网说:In MySQL, JOIN, CROSS JOIN, and INNER JOIN are syntactic equivalents (they can replace each other). JOIN, CROSS JOIN, 和 INNER JOIN 是等价的,可以相互替换。下面的例子不再出现 CROSS JOIN 和 INNER JOIN。
直接使用 JOIN 连接两个表查询得到结果为:
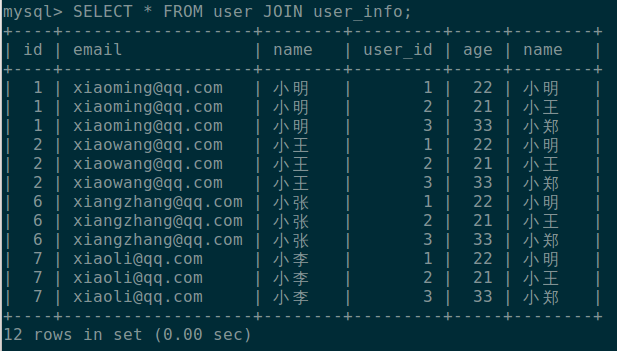
可以看到,两表结果进行了笛卡尔积,最终查出 12 行记录。这是没带任何条件的查询,这条语句等价于:
SELECT * FROM user, user_info
MySQL 官网如是说:
INNER JOIN and , (comma) are semantically equivalent in the absence of a join condition: both produce a Cartesian product between the specified tables (that is, each and every row in the first table is joined to each and every row in the second table).
说的是,在没有条件的情况下,INNER JOIN 和 ,(逗号)是等价的,都返回两张表的笛卡尔积。
我们来试试带条件的 JOIN 查询:

这个结果很清晰,连接的条件是 user.id=user_info.user_id。结果返回两行记录。
USING
我们来看看 USING 的用法:
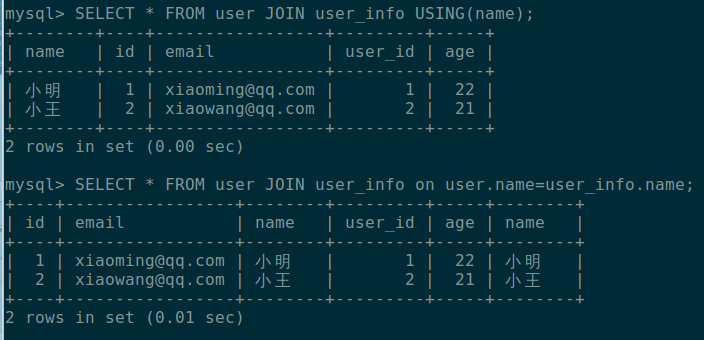
USING(name) 等价于 ON user.name=user_info.name,但是大家请注意,这里有一点点区别,使用 USING 得到的结果只有一个 name 字段,且 name 字段在结果最前面,而使用 ON 得到的结果有两个 name 字段。
我们再试试使用 USING 去查并不是两张表都有的字段:
![]()
提示错误,因为 user_info 表里并没有 id 字段。
JOIN 与 LEFT JOIN 和 RIGHT JOIN
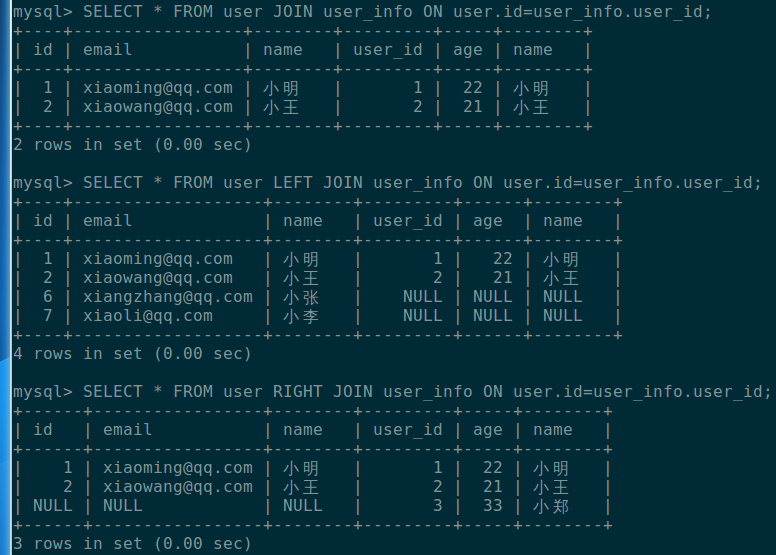
在 LEFT JOIN 里面,如果右边的表里没有匹配左边表的记录,则右边表所有字段为 NULL;同理,在 RIGHT JOIN 里面,如果左边的表里没有匹配右边表的记录,则左边表所有字段为 NULL;而 JOIN 只查询出两张表都存在的数据。
利用 LEFT JOIN 可以查出左边表存在而右边表不存在的记录,如下图:

STRAIGHT_JOIN
STRAIGHT_JOIN 和 JOIN 一样,除了前者可以保证左边的表先查。STRAIGHT_JOIN 可以用在防止 JOIN 优化器将表的顺序搞错。
NATURAL
NATURAL JOIN 等价于使用 USING,它会 USING 所有两张表里都包含的字段:

OUTER
至于这货,笔者也没搞明白是干什么的。官网给出的实例讲的是用在 ODBC 里,笔者没看明白。
上面所有的示例都只演示了两张表 JOIN,可不要以为只能两张表进行 JOIN 查询。一下是一些 SQL 示例:
SELECT * FROM t1, t2, t3;
SELECT * FROM t1 LEFT JOIN (t2 CROSS JOIN t3 CROSS JOIN t4)
ON (t2.a=t1.a AND t3.b=t1.b AND t4.c=t1.c);
ps:大家有没有发现 wordpress 写作时,编辑器用得很不爽啊,比如,插入代码后想回到正常编辑必须切换到文本模式下,在 </pre> 标签后先打几个字符然后在回可视化模式正常写作。还有,每次发文章都要跑到后台来,没有直接用 markdown 舒服啊,直接本地写好,提交上去,多方便。
PHP 实现单例模式的两种方式
第一种方式是由类维护一个静态属性,该属性是对象实例的引用,示例代码如下:
class Singleton {
private static $_instance = null;
public static function getInstance() {
is_null(self::$_instance) && self::$_instance = new self();
return self::$_instance;
}
private function __construct() { // 构造函数 private,防止类在外部被 new 出来
;
}
}
第二种方式是由静态方法里面的一个静态变量返回对象实例的引用,示例代码如下:
class Singleton {
public static function getInstance() {
static $_instance = null;
is_null($_instance) && $_instance = new self();
return $_instance;
}
private function __construct() { // 构造函数 private,防止类在外部被 new 出来
;
}
}
这两种实现有什么区别呢?效果是一样的吧~
今天才知道原来 PHP 5.3.0 之前版本是不支持延迟绑定的,赶紧把前两天写的类改过来,因为公司线上环境还是用的 5.2 系列版本。关于 PHP 延迟绑定(官网称呼其为:后期静态绑定)请看官网说明:http://www.php.net/manual/zh/language.oop5.late-static-bindings.php