What I will say in this answer is not specific to Kohana, and can probably apply to lots of PHP projects.
Here are some points that come to my mind when talking about performance, scalability, PHP, …
I’ve used many of those ideas while working on several projects — and they helped; so they could probably help here too.
First of all, when it comes to performances, there are many aspects/questions that are to consider:
- configuration of the server (both Apache, PHP, MySQL, other possible daemons, and system); you might get more help about that on ServerFault, I suppose,
- PHP code,
- Database queries,
- Using or not your webserver?
- Can you use any kind of caching mechanism? Or do you need always more that up to date data on the website?
Using a reverse proxy
The first thing that could be really useful is using a reverse proxy, like varnish, in front of your webserver: let it cache as many things as possible, so only requests that really need PHP/MySQL calculations (and, of course, some other requests, when they are not in the cache of the proxy) make it to Apache/PHP/MySQL.
- First of all, your CSS/Javascript/Images — well, everything that is static — probably don’t need to be always served by Apache
- So, you can have the reverse proxy cache all those.
- Serving those static files is no big deal for Apache, but the less it has to work for those, the more it will be able to do with PHP.
- Remember: Apache can only server a finite, limited, number of requests at a time.
- Then, have the reverse proxy serve as many PHP-pages as possible from cache: there are probably some pages that don’t change that often, and could be served from cache. Instead of using some PHP-based cache, why not let another, lighter, server serve those (and fetch them from the PHP server from time to time, so they are always almost up to date)?
- For instance, if you have some RSS feeds (We generally tend to forget those, when trying to optimize for performances) that are requested very often, having them in cache for a couple of minutes could save hundreds/thousands of request to Apache+PHP+MySQL!
- Same for the most visited pages of your site, if they don’t change for at least a couple of minutes (example: homepage?), then, no need to waste CPU re-generating them each time a user requests them.
- Maybe there is a difference between pages served for anonymous users (the same page for all anonymous users) and pages served for identified users (“Hello Mr X, you have new messages”, for instance)?
- If so, you can probably configure the reverse proxy to cache the page that is served for anonymous users (based on a cookie, like the session cookie, typically)
- It’ll mean that Apache+PHP has less to deal with: only identified users — which might be only a small part of your users.
About using a reverse-proxy as cache, for a PHP application, you can, for instance, take a look atBenchmark Results Show 400%-700% Increase In Server Capabilities with APC and Squid Cache.
(Yep, they are using Squid, and I was talking about varnish — that’s just another possibility ^^ Varnish being more recent, but more dedicated to caching)
If you do that well enough, and manage to stop re-generating too many pages again and again, maybe you won’t even have to optimize any of your code 😉
At least, maybe not in any kind of rush… And it’s always better to perform optimizations when you are not under too much presure…
As a sidenote: you are saying in the OP:
A site I built with Kohana was slammed with an enormous amount of traffic yesterday,
This is the kind of sudden situation where a reverse-proxy can literally save the day, if your website can deal with not being up to date by the second:
- install it, configure it, let it always — every normal day — run:
- Configure it to not keep PHP pages in cache; or only for a short duration; this way, you always have up to date data displayed
- And, the day you take a slashdot or digg effect:
- Configure the reverse proxy to keep PHP pages in cache; or for a longer period of time; maybe your pages will not be up to date by the second, but it will allow your website to survive the digg-effect!
About that, How can I detect and survive being “Slashdotted”? might be an interesting read.
On the PHP side of things:
First of all: are you using a recent version of PHP? There are regularly improvements in speed, with new versions 😉
For instance, take a look at Benchmark of PHP Branches 3.0 through 5.3-CVS.
Note that performances is quite a good reason to use PHP 5.3 (I’ve made some benchmarks (in french), and results are great)…
Another pretty good reason being, of course, that PHP 5.2 has reached its end of life, and is not maintained anymore!
Are you using any opcode cache?
- I’m thinking about APC – Alternative PHP Cache, for instance (pecl, manual), which is the solution I’ve seen used the most — and that is used on all servers on which I’ve worked.
- It can really lower the CPU-load of a server a lot, in some cases (I’ve seen CPU-load on some servers go from 80% to 40%, just by installing APC and activating it’s opcode-cache functionality!)
- Basically, execution of a PHP script goes in two steps:
- Compilation of the PHP source-code to opcodes (kind of an equivalent of JAVA’s bytecode)
- Execution of those opcodes
- APC keeps those in memory, so there is less work to be done each time a PHP script/file is executed: only fetch the opcodes from RAM, and execute them.
- You might need to take a look at APC’s configuration options, btw
- there are quite a few of those, and some can have a great impact on both speed / CPU-load / ease of use for you
- For instance, disabling
[apc.stat](http://php.net/manual/en/apc.configuration.php#ini.apc.stat) can be good for system-load; but it means modifications made to PHP files won’t be take into account unless you flush the whole opcode-cache; about that, for more details, see for instance To stat() Or Not To stat()?
Using cache for data
As much as possible, it is better to avoid doing the same thing over and over again.
The main thing I’m thinking about is, of course, SQL Queries: many of your pages probably do the same queries, and the results of some of those is probably almost always the same… Which means lots of“useless” queries made to the database, which has to spend time serving the same data over and over again.
Of course, this is true for other stuff, like Web Services calls, fetching information from other websites, heavy calculations, …
It might be very interesting for you to identify:
- Which queries are run lots of times, always returning the same data
- Which other (heavy) calculations are done lots of time, always returning the same result
And store these data/results in some kind of cache, so they are easier to get — faster — and you don’t have to go to your SQL server for “nothing”.
Great caching mechanisms are, for instance:
- APC: in addition to the opcode-cache I talked about earlier, it allows you to store data in memory,
- And/or memcached (see also), which is very useful if you literally have lots of data and/or areusing multiple servers, as it is distributed.
- of course, you can think about files; and probably many other ideas.
I’m pretty sure your framework comes with some cache-related stuff; you probably already know that, as you said “I will be using the Cache-library more in time to come” in the OP 😉
Profiling
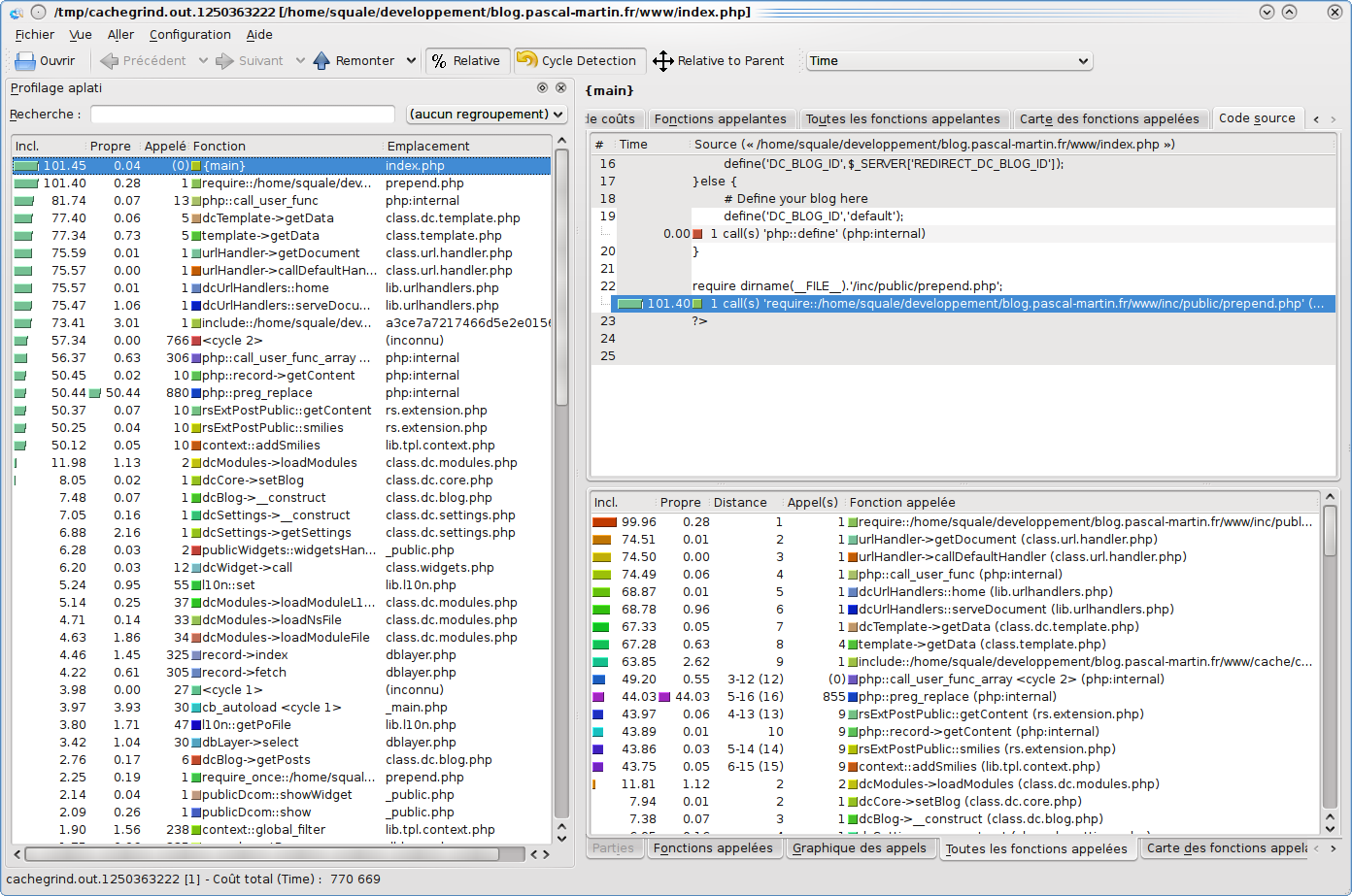
Now, a nice thing to do would be to use the Xdebug extension to profile your application: it often allows to find a couple of weak-spots quite easily — at least, if there is any function that takes lots of time.
Configured properly, it will generate profiling files that can be analysed with some graphic tools, such as:
- KCachegrind: my favorite, but works only on Linux/KDE
- Wincachegrind for windows; it does a bit less stuff than KCacheGrind, unfortunately — it doesn’t display callgraphs, typically.
- Webgrind which runs on a PHP webserver, so works anywhere — but probably has less features.
For instance, here are a couple screenshots of KCacheGrind:

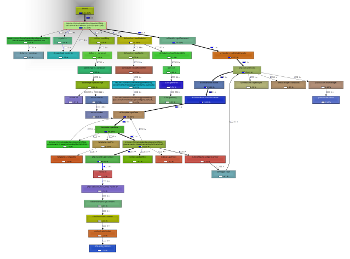
(BTW, the callgraph presented on the second screenshot is typically something neither WinCacheGrind nor Webgrind can do, if I remember correctly ^^ )
(Thanks @Mikushi for the comment) Another possibility that I haven’t used much is the the xhprofextension : it also helps with profiling, can generate callgraphs — but is lighter than Xdebug, which mean you should be able to install it on a production server.
You should be able to use it alonside XHGui, which will help for the visualisation of data.
On the SQL side of things:
Now that we’ve spoken a bit about PHP, note that it is more than possible that your bottleneck isn’t the PHP-side of things, but the database one…
At least two or three things, here:
- You should determine:
- What are the most frequent queries your application is doing
- Whether those are optimized (using the right indexes, mainly?), using the
EXPLAIN instruction, if you are using MySQL
- whether you could cache some of these queries (see what I said earlier)
- Is your MySQL well configured? I don’t know much about that, but there are some configuration options that might have some impact.
Still, the two most important things are:
- Don’t go to the DB if you don’t need to: cache as much as you can!
- When you have to go to the DB, use efficient queries: use indexes; and profile!
And what now?
If you are still reading, what else could be optimized?
Well, there is still room for improvements… A couple of architecture-oriented ideas might be:
- Switch to an n-tier architecture:
- Put MySQL on another server (2-tier: one for PHP; the other for MySQL)
- Use several PHP servers (and load-balance the users between those)
- Use another machines for static files, with a lighter webserver, like:
- lighttpd
- or nginx — this one is becoming more and more popular, btw.
- Use several servers for MySQL, several servers for PHP, and several reverse-proxies in front of those
- Of course: install memcached daemons on whatever server has any amount of free RAM, and use them to cache as much as you can / makes sense.
- Use something “more efficient” that Apache?
- I hear more and more often about nginx, which is supposed to be great when it comes to PHP and high-volume websites; I’ve never used it myself, but you might find some interesting articles about it on the net;
Well, maybe some of those ideas are a bit overkill in your situation ^^
But, still… Why not study them a bit, just in case ? 😉
And what about Kohana?
Your initial question was about optimizing an application that uses Kohana… Well, I’ve posted someideas that are true for any PHP application… Which means they are true for Kohana too 😉
(Even if not specific to it ^^)
I said: use cache; Kohana seems to support some caching stuff (You talked about it yourself, so nothing new here…)
If there is anything that can be done quickly, try it 😉
I also said you shouldn’t do anything that’s not necessary; is there anything enabled by default in Kohana that you don’t need?
Browsing the net, it seems there is at least something about XSS filtering; do you need that?
Still, here’s a couple of links that might be useful:
Conclusion?
And, to conclude, a simple thought:
- How much will it cost your company to pay you 5 days? — considering it is a reasonable amount of time to do some great optimizations
- How much will it cost your company to buy (pay for?) a second server, and its maintenance?
- What if you have to scale larger?
- How much will it cost to spend 10 days? more? optimizing every possible bit of your application?
- And how much for a couple more servers?
I’m not saying you shouldn’t optimize: you definitely should!
But go for “quick” optimizations that will get you big rewards first: using some opcode cache might help you get between 10 and 50 percent off your server’s CPU-load… And it takes only a couple of minutes to set up 😉 On the other side, spending 3 days for 2 percent…
Oh, and, btw: before doing anything: put some monitoring stuff in place, so you know what improvements have been made, and how!
Without monitoring, you will have no idea of the effect of what you did… Not even if it’s a real optimization or not!
For instance, you could use something like RRDtool + cacti.
And showing your boss some nice graphics with a 40% CPU-load drop is always great 😉
Anyway, and to really conclude: have fun!
(Yes, optimizing is fun!)
(Ergh, I didn’t think I would write that much… Hope at least some parts of this are useful… And I should remember this answer: might be useful some other times…)
原文链接:http://stackoverflow.com/questions/1260134/optimizing-kohana-based-websites-for-speed-and-scalability